
Map/Reduce
Um sehr große Datenmengen effizient bearbeiten zu können, hat Google das Map/Reduce-Verfahren entwickelt und 2004 vorgestellt [5] . Mittlerweile ist es patentiert. Die Grundlagen dieses Verfahrens waren allerdings schon seit vielen Jahrzehnten in der funktionalen Programmierung geläufig.
Kernidee dieses Verfahrens ist, Daten zu segmentieren und dann von sehr vielen Prozessen bearbeiten zu lassen ( Abbildung 3 ). Das läuft im Wesentlichen auf das Sammeln und gegebenenfalls Transformieren und Verdichten der Daten heraus, so wie man eine Ameisen- oder Bienenarmee beauftragen würde. Die Daten werden dazu typischerweise in 16 bis 64 MByte große Blöcke zerlegt. Ein Master-Prozess weist dann den Worker-Prozessen zuerst eine Map-Aufgabe zu. Dabei müssen die Key/Value-Paare der Daten analysiert und gesammelt werden. Die Ergebnisse werden dann weiteren Workern übergeben, die das Reduce ausführen und die Daten verdichten.
Dieses Verfahren ist hochparallelisierbar und gut für Aufgaben geeignet wie verteiltes Suchen, das Zählen von URL-Zugriffe und Web-Verlinkungen, Indexe erstellen und so weiter. Daher wird es von sehr vielen NoSQL-Datenbanken als Operation angeboten. Vorteil ist weiterhin, dass die Map- und Reduce-Funktionen in jeder Programmiersprache formuliert werden können. Die Forschung arbeitet derzeit fieberhaft an weiteren Modellen, die Vorteile beider Welten – extreme Parallelisierbarkeit und die Mächtigkeit relationaler Abfragen – zu integrieren versucht.
CAP
Als einer der ersten hat Amazon mit dem Dynamo-System aufgezeigt und darüber publiziert [6] , wie man extrem große Datenmengen so verwaltet, dass die zugrunde liegenden Systeme hochverfügbar sind. Da Amazon viele Dutzend Millionen Anwender gleichzeitig bedienen muss, ist Hochverfügbarkeit ein wichtiges Thema. Dabei darf der Ausfall von Rechnerknoten keine negativen Auswirkungen haben (Partition Tolerance). Andere Knoten müssen einspringen können, und das System muss immer reagieren. Firmen wie Google, Yahoo oder Amazon verlieren sehr viele Millionen Dollar in jeder Minute Downtime. Wenn man auf Availability und Partition Toleranz setzt, zeigt es sich jedoch, dass man keine hundertprozentige Konsistenz aufrechterhalten kann, da Knoten Zeit brauchen, um zu replizieren. Man gibt daher ACID-Transaktionalität zugunsten des BASE-Modells (Basically Available, Soft State, Eventually Consistent) auf. Eventual Consistency bedeutet, dass es möglich sein kann, dass Knoten zum Beispiel für wenige Zehntelsekunden einen unterschiedlichen Stand haben und ein Client in seltenen Fällen einen älteren Zustand "sieht". Dies ist bei sicherheitskritischen Systemen wie Bankanwendungen inakzeptabel. Bei Web-2.0-Systemen wie Social Networks ist es jedoch absolut kein Problem. Ob ein Tweet oder eine Gefällt-mir-Bekundung sofort oder eine Sekunde später sichtbar wird, interessiert nicht wirklich.
Wie in Abbildung 4 gezeigt, bilden die drei Punkte Availability, Consistency und Partition Tolerance das CAP-Theorem-Dreieck, für das Eric Brewer schon im Jahre 2000 gezeigt hat, dass nur zwei dieser drei Ziele gleichzeitig erreichbar sind.
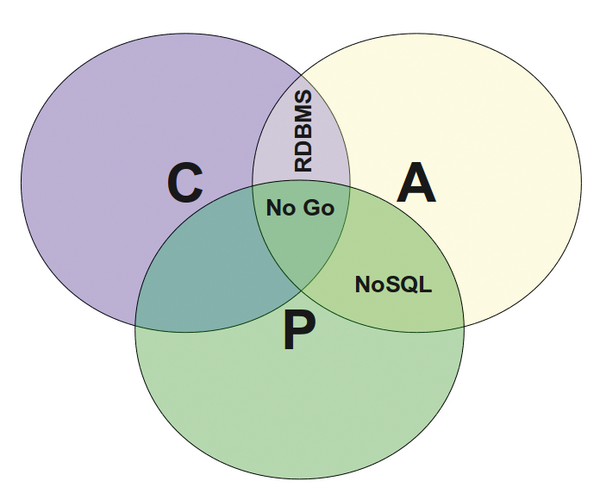 Abbildung 4: Das CAP-Theorem – nur zwei der drei Bedingungen sind jeweils gleichzeitig realisierbar.
Abbildung 4: Das CAP-Theorem – nur zwei der drei Bedingungen sind jeweils gleichzeitig realisierbar.
Consistent Hashing ist eine Methode, die es erlaubt, eine Gruppe von Rechnerknoten (Nodes) mit besonders geringem Aufwand zu verkleinern oder zu vergrößern. Eine Veränderung hat dann nämlich meistens nur Auswirkungen auf Nachbarknoten, wogegen bei konventionellen Verfahren häufig so gut wie alle Knoten betroffen sind. Dazu baut man einen Ring ( Abbildung 5 ) wie folgt auf: Alle Elemente der Datenbank werden mit einem geeigneten Hashverfahren wie MD5 auf einen Adressraum abgebildet, beispielsweise von 0 bis 2^160. Dieser Adressraum wird dann auf Rechnerknoten aufgeteilt. Bei Bedarf können die Rechnerknoten wieder virtuelle Nodes enthalten. Jedes Datenbankobjekt bekommt nun eine eindeutige Position im Ring. Jeder Node kann nun auf N weitere Nodes replizieren und so für weitere Sicherheit sorgen. Dieses System ist dann einfach rekonfigurierbar.
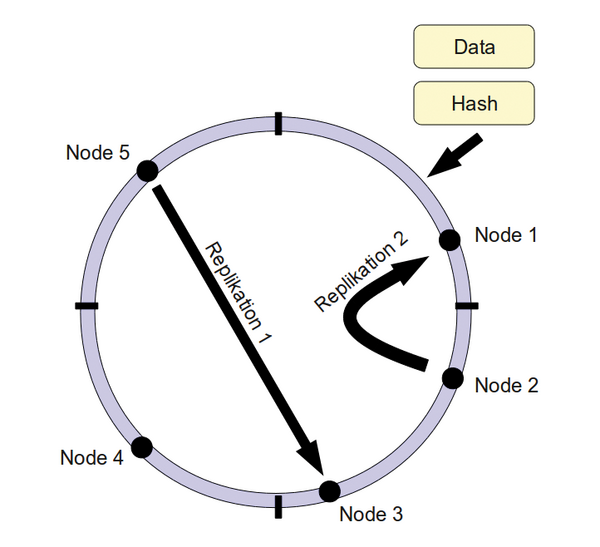 Abbildung 5: Consistent Hashing Ring: Jedes Datenbankobjekt hat eine eindeutige Position im Ring und kann auf andere Nodes replizieren.
Abbildung 5: Consistent Hashing Ring: Jedes Datenbankobjekt hat eine eindeutige Position im Ring und kann auf andere Nodes replizieren.
Multi Version Concurrency Control (MVCC): Dieses Verfahren sei anhand einer Analogie zur Versionskontrolle veranschaulicht. Viele Versionskontrollsysteme in den 90er-Jahren arbeiteten mit Locks (pessimistische Sperrverfahren). Zwei Softwareentwickler konnten nicht gleichzeitig dieselbe Datei editieren. Einer musste warten, bis der Lock aufgelöst war. Es hat sich jedoch gezeigt, dass dieses Verfahren bei vielen Entwicklern (in hochgradig verteilten und parallelen Systemen) nicht immer praktikabel ist. Daher setzen Subversion und besonders moderne Systeme wie Git und Mercurial darauf, nicht zu sperren, sondern stattdessen mit Versionen zu arbeiten (optimistische Sperrverfahren). Oftmals ist es nämlich viel leichter, sehr seltene Konflikte zu lösen, als ständig in Locks hängenzubleiben. Das Gleiche gilt ganz allgemein für parallel schreibende Systeme, die den gleichen Datenbestand bearbeiten möchten.
Verwendet man wie bei MVCC einfach nummerierte Versionen, dann kann es zwar sein, dass Prozesse ältere Versionen erhalten oder dass zwei Transaktionen zwei verschiedene Versionen des gleichen Objektes schreiben, aber das Objekt ist nicht mehr gesperrt. Nach anfänglicher Zurückhaltung der Industrie ist dieses Verfahren nicht nur bei NoSQL-Datenbanken, sondern auch in allen bedeutenden relationalen Datenbanken und sogar in Programmiersprachen wie Clojure implementiert [8] .
Vector Clocks sind ein wichtiges Mittel in verteilten Systemen, um zeitliche Zusammenhänge zu erkennen. Oftmals können oder möchten sich Systeme nicht auf reale Uhren wie Unix Epoch-Zeitstempel verlassen. In diesem Fall werden einfach eindeutige Identifier (IDs wie beispielsweise eine Prozess ID) zusammen mit einem persönlichen Counter versendet, die eine Nachricht eindeutig auszeichnen.
Mit dieser Menge an IDs und Zeitstempeln liefert der Vektor die Möglichkeit, Ereignisse wie das Schreiben in eine Datenbank zeitlich zu ordnen. Viel wichtiger ist es aber zu erkennen, dass das Schreiben eines Wertes X die Ursache eines anderen Ereignisses ist. Dies ermöglicht es Clients, selbst zu entscheiden, welche Version eines Objektes jetzt die beste oder aktuellste ist [9] . Wer dagegen eine Einigung aller Teilnehmer erreichen möchte, muss unter Umständen auf komplexere Protokolle wie Paxos zurückgreifen [10] .
Wide Column Stores oder auch Column Families fühlen sich ein bisschen wie eine Mischung aus relationalen Tabellen und Excel-Sheets an. Kennzeichnend ist, dass die unterste Ebene meistens Schlüssel und Werte speichert, ähnlich einer Tabelle. Eine beliebige Anzahl dieser Schlüssel-Wert-Paare lassen sich dann meist in einer Column Family zusammenfassen, die wiederum selbst einen Schlüssel repräsentiert. Auf oberster Ebene steht dann meistens noch eine Domain oder ein Keyspace zur Verfügung. Der Aufbau ist also meistens der:
Keyspace x ColumnFamily x (Key -> Value*)
Die bekanntesten Vertreter, die alle auf die Verarbeitung extrem großer Datenmengen ausgelegt sind, heißen:
- Hadoop / HBase (Hypertable, Cloudera)
- Cassandra
- Amazon SimpleDB
Hadoop/HBase ist das Pendant zu Googles BigTable und wurde von Yahoo initiiert. Dabei ist Hadoop das komplette Apache-Projekt mit vielen Unterprojekten. HBase definiert nun das spaltenorientierte Datenbanksystem als mehrdimensionales assoziatives Array auf der Hadoop-Infrastruktur wie dem Hadoop Filesystem (HDFS). Der Zugriff erfolgt über Java, REST und Thrift.
Hypertable ist im Gegensatz zu Hadoop/ HBase (Java) in C++ geschrieben. Dadurch ist es deutlich schneller und ressourcenschonender als Hadoop. Es wird zum Beispiel bei Baidu eingesetzt, dem Konkurrenten der Google-Suchmaschine in China. Für Hadoop und Hypertable gibt es viele solcher Beispiele für wirklich extrem große Installationen. Cloudera bietet Services und Werkzeuge rund um Hadoop an.
Die Datenbanken dieser Gruppe bieten einfachste Skalierung durch Hinzufügen eines Region-Servers mit handelsüblicher Hardware. Sie verfügen über eine starke Community und lassen sich leicht aufsetzen, das Optimieren und Warten ist allerdings komplex. Die Replikation funktioniert nur auf Filesystem-Ebene.
Amazon SimpleDB: Dieser Datenbank-Dienst ist Teil der der Amazon Web Services (AWS), in die er sich nahtlos in eingliedert. Da es sich um einen proprietären Cloud-Service handelt (SaaS), ist SimpleDB nicht lokal installierbar. Als Cloud Service zahlt man ähnlich wie bei EC2 jeweils Gebühren für Übertragung, Anfragen und Speicher. Der Zugriff erfolgt via REST, SOAP, Java, C#, Perl, PHP, Javascript oder über das HTTP-Protokoll. Angenehm ist, dass die Datenbank automatisch skaliert. Dabei ist es möglich, auf etwas Konsistenz zugunsten der Performance zu verzichten. Das Datenmodell ist ähnlich dem obigen allgemeinen:
Domains x Items x Attributes, Values.
Dabei können dynamisch beliebige viele neue Attribute angelegt werden.
Cassandra: Die NoSQL Datenbank Cassandra entstammt Facebook. Google BigTable war hier zwar ebenfalls Vorbild, das Datenmodell ist aber eher hybrid, da ein festes Schema erweitert werden kann. Die API ist komplett auf Thrift ausgelegt. Cassandra ist komplett in Java geschrieben und dennoch relativ schnell. Ziel war es auch hier, den Cassandra-Ring sehr leicht dynamisch erweitern zu können. Das Datenmodell Abbildung 6 anhand eines einfachen Beispiels.
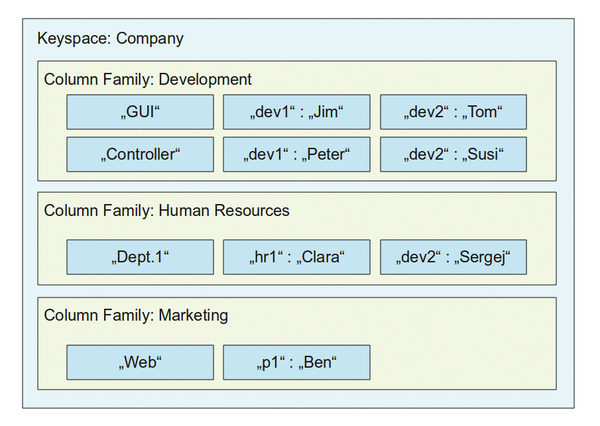 Abbildung 6: Das Datenmodell von Cassandra: Schlüssel verweisen auf weitere Schlüssel-Wert-Paare innerhalb von Column Families und Keyspaces.
Abbildung 6: Das Datenmodell von Cassandra: Schlüssel verweisen auf weitere Schlüssel-Wert-Paare innerhalb von Column Families und Keyspaces.
Die Daten in Cassandra bestehen aus beliebig vielen Keyspaces. Darin sind beliebig viele Column Families enthalten. Beide müssen leider in einer XML-Datei bekannt gemacht werden. Danach folgen beliebig viele Zeilen, die links durch einen Key ("GUI", "Controller" und so weiter) identifiziert werden und als Hash dann auf beliebig viele Werte verweisen. Cassandra erlaubt dabei sogar mit Super Columns eine weitere Schachtelungstiefe, in der eine Liste statt eines Values angegeben werden kann. Eine Einfügeoperation erfolgt dann beispielsweise in Ruby ganz einfach mit:
# Der Keyspace
siemens = Cassandra.new("Siemens")
gui = {"dev1" => "Jim", "dev2" => "Tom"}
siemens.insert(:Development, "GUI", gui)
Cassandra ist einfach skalierbar, Replikation, Konsistenz und Latenzzeit der Antworten sind leicht konfigurierbar. Einen Single Point of Failure gibt es nicht. Allerdings ist es bisher nicht möglich, das Schema im laufenden Betrieb zu ändern.
Ähnliche Artikel
-
CouchDB-Gründer verabschiedet sich von Apache-Projekt
Der Erfinder der NoSQL-Datenbank CouchDB wendet sich vom Apache-Projekt ab und widmet sich der Neuentwicklung seiner Datenbank unter dem Namen Couchbase. Im CouchDB-Markt konkurrierende Unternehmen stecken nun ihre Felder ab.
-
NoSQL-Datenbanken lokal und in der Cloud

-
Alternativen zu SQL

-
Microsoft veröffentlicht Redis für Windows
Die neue Initiative Microsoft Open Technologies legt als erstes freies Produkt einen Port der NoSQL-Datenbank Redis für Windows vor.
-
Tipps, Tricks & Tools

Konfigurationsmanagement

Themen


