Oracle Database 12c: Cloud Computing mit Multitenant-Architektur

Datenbank zum Einstöpseln

Rund fünf Jahre Entwicklungszeit waren für das neue Release erforderlich. Die eigentliche Veröffentlichung erfolgte dann eher still und leise, ohne Paukenschlag und großes Tamtam, wie sonst üblich. Die aktuelle Version kann seit Ende Juni aus dem Oracle Technology Network (OTN) heruntergeladen werden. Sie sollte eigentlich früher veröffentlicht werden, dann musste man aber doch etwas länger testen, um eine möglichst fehlerfreie Software auf den Markt zu bringen.
Aktuell steht das neue Release für Linux und Solaris zur Verfügung. Versionen für Windows, IBM AIX und HPUX sollen in Kürze folgen. Auch ein Release für BS2000-Plattformen wird es wieder geben. Für die Aktualisierung will der Hersteller erneut spezielle Upgrade-Assistenten bereitstellen. Sogar der direkte Schritt von der älteren Releases 8i und 9i auf 12c soll möglich sein. Voraussetzung hierfür ist, dass die Datenbank den aktuellen Patch-Stand aufweist.
Oracle will über die bekannten Lizenzmodelle hinaus auch einen eigenen Cloud-Dienst mit flexiblen Preisen anbieten. Ob und wie dies bei den Kunden ankommen wird, ist eine spannende Frage: Nicht erst nach den jüngsten Berichten über PRISM stehen viele Unternehmenskunden den Public-Cloud-Modellen eher skeptisch gegenüber. Doch neben der Public Cloud gibt es künftig einfache Möglichkeiten, auch im eigenen Unternehmen mit der neuen Multitenant-Architektur eine flexible und gut konsolidierbare Datenbank-Landschaft bereitzustellen. Die neue Multitenant-Architektur bildet so eine Voraussetzung für Database as a Service.
Neues Paradigma
Eine der wichtigsten Neuerungen ist die Mandantenfähigkeit der neuen Architektur. Sie soll Cloud Computing erleichtern, gleich ob in einer öffentlichen oder in der Private Cloud eines Unternehmens. Aber auch Hardware-Ressourcen und der Verwaltungsaufwand lassen sich so reduzieren.
Die neue Architektur wird vor allem jenen Kunden zugutekommen, die bisher zahlreiche einzelne Instanzen im Einsatz haben. Bis zu 253 Datenbanken können nun in eine Instanz gepackt werden. So sollen sich Hardware-Kapazitäten wie Arbeitsspeicher, CPU-Leistung und Storage gemeinsam und effizienter nutzen lassen. Auch das Einspielen von Patches, Upgrades der Datenbanksoftware sowie Backup- und Recovery-Funktionen werden einfacher ( Abbildung 2 ).
 Abbildung 2: Auch das notwendige Updaten und Patchen der Datenbank macht das neue Oracle-Release für den Administrator nun deutlich einfacher.
Abbildung 2: Auch das notwendige Updaten und Patchen der Datenbank macht das neue Oracle-Release für den Administrator nun deutlich einfacher.
Bei dem Konzept der Pluggable Database handelt es sich um eine grundsätzliche Veränderung des bisherigen Oracle-Paradigma, demzufolge eine Instanz (oder mehrere Instanzen eines Clusters) immer nur genau eine Datenbank öffnen konnten. Mit der Einführung der Pluggable Database ändert sich das: Es ist möglich, mit einer Instanz mehrere Datenbanken zu öffnen und zu betreiben. Oracle zielt damit auf eine maximale Datenbank-Konsolidierung ab, ohne das dafür Virtualisierung nötig wäre. Nach Meinung der Autoren kann die neue Architektur die Virtualisierung auf Hostebene in großen Umgebungen überflüssig machen.
Um dies zu erreichen, erweitert Oracle die Datenbank um eine weitere Ebene: Es gibt zukünftig die sogenannte Container Database (CDB), die bis zu 253 Pluggable Databases (kurz: PDBs) aufnimmt ( Abbildung 1 ). Diese erscheinen für den Anwender wie normale Datenbanken – und sie verhalten sich auch so. Anpassungen am Programmcode einer Anwendung sind bis auf ganz wenige Fälle nicht notwendig, da der Namensraum jeder Datenbank individuell ist.
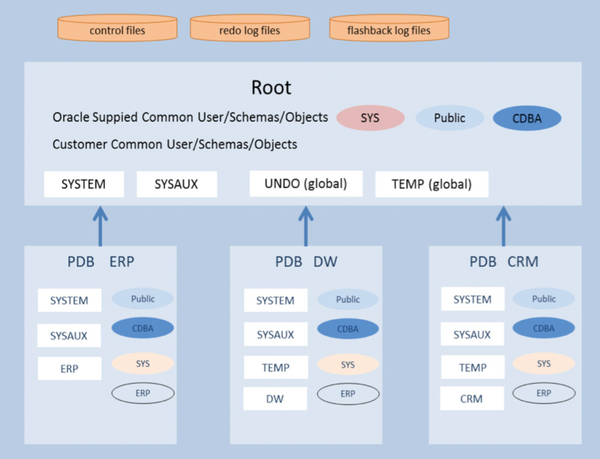 Abbildung 1: Eine Container Database nimmt mehrere Pluggable Databases auf.
Abbildung 1: Eine Container Database nimmt mehrere Pluggable Databases auf.
Die CDB selbst ist eine Instanz mit zugehörigem Speicher und Prozessen (wie zum Beispiel dem Logwriter LGWR, dem DBWriter DBWn, Checkpointer CKPT, und so weiter). Die PDBs dagegen haben keine eigenen Hintergrundprozesse – die Verarbeitung wird von den Hintergrundprozessen der Container Database erledigt.
Das Data Dictionary mit den Metadaten speichert – wie in den Releases zuvor – Informationen wie Benutzer und Berechtigungen, Informationen über Tabellen, Indizes, Views und alle weiteren Datenbankobjekte. Dieses Data Dictionary wird in der Multitenant-Architektur jedoch in der CDB gespeichert. Die einzelnen PDBs haben intern lediglich Pointer auf die entsprechenden Bereiche in der Container Database. In ihr sind die Objekte des Data Dictionary definiert. Die eigentlichen Daten des Data Dictionary wie zum Beispiel die Rows in der Tabelle
»OBJ$«
sind in den jeweiligen Pluggable Databases abgelegt, sodass diese Daten beim Kopieren der Datenbank mitgenommen werden können.
Effizienter durch Container
Dieses Konzept ermöglicht die Trennung von Metadaten – also der Beschreibung des Data Dictionary – von den eigentlichen Daten, dem Inhalt des Data Dictionary. Zum einen ist es dadurch möglich, die einzelnen PDBs beliebig zu transportieren. Sie können entweder innerhalb eines oder auch zwischen verschiedenen Containern verlegt werden. Zum anderen erlaubt dies ab der Version 12c schnellere Upgrades: Statt wie bisher das Data Dictionary mittels
»catproc«
upzugraden, genügt es künftig, die PDB in eine Container Database der Version 12c+1 "einzupluggen", um diese auf die Nachfolgeversion zu aktualisieren.
Wie bereits beschrieben verfügen die einzelnen PDBs über keine eigenen Speicherbereiche oder Prozesse. Hierdurch wird eine bessere Auslastung der Ressourcen erreicht, da zum einen wesentlich weniger Prozesse um die verfügbaren CPU-Kerne konkurrieren und so weniger Context-Switches notwendig werden, und zum anderen wesentlich mehr Speicher für den Buffer Cache oder den Shared Pool bereitsteht, da die mindestens 350 MByte SGA für den Betrieb einer Instanz für die CDB und nicht für die PDBs gelten. Dies kann man sich mit einem einfachen Rechenbeispiel vergegenwärtigen: Bei zehn Datenbanken in der Version 11g werden mindestens 10 x 350 MByte, also rund 3,5 GByte Speicher benötigt, um jede Instanz für sich überhaupt starten zu können. Der Buffer Pool und der Shared Pool haben hier kaum Platz, um ihren Funktionen nachkommen zu können. Ebenso hat man als Resultat mindestens 10 x 6 Hintergrundprozesse, die um die CPU konkurrieren. Nutzt man nun das Konzept der Pluggable Databases und lässt die zehn Datenbanken als PDBs in einer CDB laufen, so bleiben davon lediglich 6 Prozesse und 350 MByte Speicher zum Betreiben der CDB übrig. Die restlichen 3,15 GByte im Vergleich zur alten Architektur kann man mit dem neuen Konzept bereits für den Buffer Cache oder den Shared Pool nutzen.
Ähnliche Artikel
-
Neu: Oracle Enterprise Manager 12c
Mit einem neuen zentralisierten Administrationswerkzeug, dem Oracle Enterprise Manager 12c, will Oracle seine Multitennant-Architektur für pluggable Databases as a Service (DBaaS) weiter voran bringen.
-
Ausblick auf Oracle 12
Im Rahmen eines Pressebriefings im Nachgang der eben beendeten Hausmesse Oracle Openworld in San Francisco gab der Hersteller einen kleinen Ausblick auf die im kommenden Frühjahr zu erwartende Version 12c seiner Datenbank.
-
Oracle-Datenbanken per PowerShell ansprechen

-
Buchbesprechung

-
TimesTen in Version 2
Oracles In-Memory-Datenbank TimesTen ist jetzt in einer neuen Version erschienen.
Konfigurationsmanagement

Themen


