GlusterFS als Container-Storage

Dauerhaft gesichert

Bildeten zu Anfang noch virtuelle Maschinen die Grundlage Cloud-basierter Umgebungen, so helfen heute Container dabei, die Cloud-Landschaft zu stärken und auszubauen. Anders als virtuelle Maschinen benötigen Container keinen Hypervisor und auch kein eigenes Betriebssystem mehr und laufen somit unmittelbar innerhalb des Systems, auf dem die Container gestartet werden. Das freut nicht nur Entwickler, die so sehr schnell selbständig neue Container provisionieren können, um darin Anwendungen entwickeln, deployen und testen zu können, sondern auch System-Administratoren, da sich Container sehr leicht verwalten lassen und es bei der Installation von Anwendungen weniger häufig zu Abhängigkeitsproblemen kommt. Auch IT-Verantwortliche freuen sich nicht nur wegen der geringeren Kosten, die Container mit sich bringen, sondern auch wegen der gesteigerten Produktivität ihrer Teams. Neue Container lassen sich innerhalb von Sekunden zur Verfügung stellen. Stillstand, weil ein Team auf die Bereitstellung von neuen Systemen warten muss, enfällt somit in den meisten Fällen.
Flüchtige Container
Ein weiterer Unterschied zwischen Containern und virtuellen Maschinen besteht darin, dass Container eher als kurzlebige Objekte angesehen werden, während virtuelle Maschinen mehr für einen langfristigen Einsatz vorgesehen sind. Daher rührt auch das oft gebrauchte Meme von Pets vs. Cattle, wobei virtuelle Maschinen die netten Haustiere mit Namen darstellen und Container eher die anonymen Viecher ohne Namen. Dies erklärt auch den Umstand, dass Container zu Beginn ihrer Erfolgsgeschichte oftmals lediglich für Stateless-Applikationen eingesetzt wurden. Warum das so ist, wird schnell klar, wenn man sich den Lifecycle eines Containers einmal näher ansieht.
Typischerweise wird ein solcher Container auf einem beliebigen Host innerhalb der Cloud-Landschaft gestartet. Als Grundlage hierfür dient ein bestimmtes Container-Image. Daten innerhalb des Containers lassen sich auf einem beschreibbaren Layer des Images verändern beziehungsweise neu erzeugen, allerdings sind diese Änderungen mit dem Beenden des Containers wieder verloren. Um diese Daten dauerhaft zu erhalten, können Container sogenannte Daten-Volumes einbinden. Hierbei handelt es sich um Directories innerhalb des Host-Systems, die den Containern, die auf diesem Host laufen, zur Verfügung gestellt werden. Hier ein Beispiel für das Einbinden eines Daten-Volumes in einen Docker-Container:
# docker run -d -P --name web -v /data:/www/webapp fedora/httpd python app.py
Der Ordner "/data" auf dem Host steht nun innerhalb des Containers als "/www/webapp" zur Verfügung. Eine weitere Möglichkeit besteht darin, sogenannte Daten-Volume-Container zu verwenden. Hierbei hat ein bestimmter Container lediglich die Aufgabe, bestimmte Volumes zur Verfügung zu stellen, die andere Container beim Starten mit der Option "--volumes-from" einbinden können.
Natürlich bringen diese Ansätze mehrere Probleme mit sich. Wer Orchestrierungstools zum Management der Container einsetzt, der weiß wahrscheinlich gar nicht, auf welchem Host ein Container tatsächlich gestartet wird. Selbst wenn dies klar ersichtlich ist, so ist es durchaus üblich, dass der gleiche Container vielleicht zu einem späteren Zeitpunkt auf einem ganz anderen Host läuft. Dies kann beispielsweise dann der Fall sein, wenn der ursprüngliche Host ausgefallen ist oder auch wenn der Admin entschieden hat, dass mehrere Container des gleichen Typs notwendig sind, und diese zur besseren Skalierung auf unterschiedlichen Host-Systemen gestartet werden.
Dem Container-Administrator sollen die Ressourcen der Cloud-Umgebung ja gerade nicht mehr als einzelne Silos erscheinen, sondern als gemeinsame Ressource für alle Systeme zur Verfügung stehen. Zu welchem Host CPUs, RAM-Speicher oder Daten-Volumes gehören, darf dabei keine Rolle mehr spielen. Somit ist der Zugriff auf lokale Daten-Volumes im praktischen Einsatz von Containern eher nicht zu empfehlen.
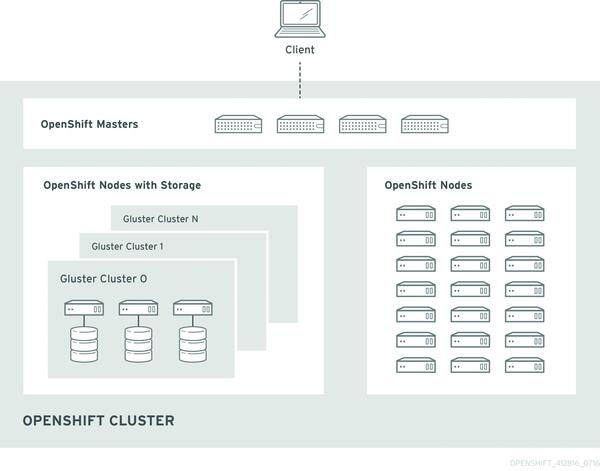 Bild 1: Innerhalb von OpenShift lässt sich der Storage entweder über Gluster-Container bereitstellen ...
Bild 1: Innerhalb von OpenShift lässt sich der Storage entweder über Gluster-Container bereitstellen ...
Storage für Stateful-Container
Wie könnte nun eine Lösung für Stateful-Container aussehen, bei der Daten nicht mit dem Beenden des Containers verloren gehen und auch innerhalb eines kompletten Container-Clusters zur Verfügung stehen? Die Antwort auf diese Frage lautet Software-defined Storage (SDS), der als persistenter Speicher für Container zur Verfügung gestellt wird. CoreOS hat mit Torus [1] vor einiger Zeit bereits eine solche Software auf Basis von verteilten Speichersystemen zur Verfügung gestellt.
Der Linux-Distributor Red Hat geht noch einen Schritt weiter und stellt mit dem aktuellen Release seiner PaaS-Lösung OpenShift Container Platform [2] sogenannten Hyper-Converged Storage zur Verfügung. Was heisst das nun im Detail? Vereinfacht gesagt bedeutet dies nichts anderes, als dass Computer- und Speicherressourcen zusammengeführt werden und über die gleiche Container-Management-Software deployed und verwaltet werden. Computer- und Storage-Container existieren somit parallel innerhalb des gleichen Cloud-Frameworks, in diesem Fall der OpenShift Container Platform. Beim Anlegen eines Containers gibt der Nutzer einfach an, aus welchem Storage-Cluster er zugreifen möchte und wie groß das benötigte Volume sein soll. Bei der Definition eines Containers über eine YAML-Datei wird dieses Volume dann als zusätzliche Ressource aufgeführt. Der Container bekommt den Speicher beim Starten zugewiesen, der unabhängig vom Lifecycle des Containers dauerhaft zur Verfügung steht. Red Hat setzt dazu auf Gluster Storage, der innerhalb von OpenShift-Containern bereitgestellt wird. Bei Bedarf kann er aber auch über einen externen Storage-Cluster eingebunden werden, was dann aber natürlich zur Folge hat, dass keine Hyper-Converged Lösung mehr zur Verfügung steht.
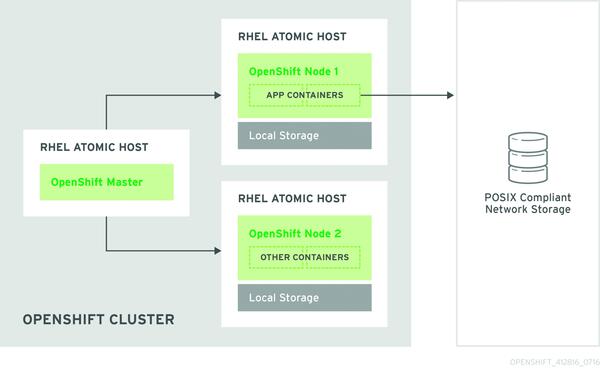 Bild 2: ... oder über einen externen Storage-Cluster, in dem einzelne Gluster-Nodes laufen.
Bild 2: ... oder über einen externen Storage-Cluster, in dem einzelne Gluster-Nodes laufen.
Möglich macht das Ganze ein neuer Service in Gluster 3.1.3: Heketi. Er stellt eine RESTful API zur Verfügung, die sich von diversen Cloud-Frameworks wie etwa OpenShift oder OpenStack ansprechen lässt, um so dynamisch das gewünschte Speicher-Volume zu provisionieren. Dieses wird innerhalb des Containers als persistentes Volume eingebunden. Das manuelle Anlegen von Gluster-Storage-Pools entfällt somit. Stattdessen kümmert sich der neue Service Heketi darum, alle registrierten Gluster-Nodes in Clustern zu organisieren, Storage-Pools zu erzeugen und die gewünschten Volumes auf Anfrage zur Verfügung zu stellen.
Das Beispiel in diesem Artikel basiert auf der Red Hat OpenShift Container Platform 3.2. Innerhalb dieser Umgebung kommen Gluster Storage Nodes in der Version 3.1.3 zum Einsatz, die selbst als Container innerhalb von OpenShift implementiert sind. Sämtliche praktischen Beispiele setzen voraus, dass eine entsprechende OpenShift-Installation bereits vorhanden ist, da die Beschreibung des kompletten Setups den Rahmen dieses Artikels sprengen würde. Die Installation sollte bereits über ein vorhandenes Heketi-Setup verfügen und ein OpenShift-Projekt sollte ebenfalls bereits existieren. Eine Beschreibung zur Installation von OpenShift [3], dem Heketi-Service und den Gluster-Storage-Containern findet sich im Web [4].
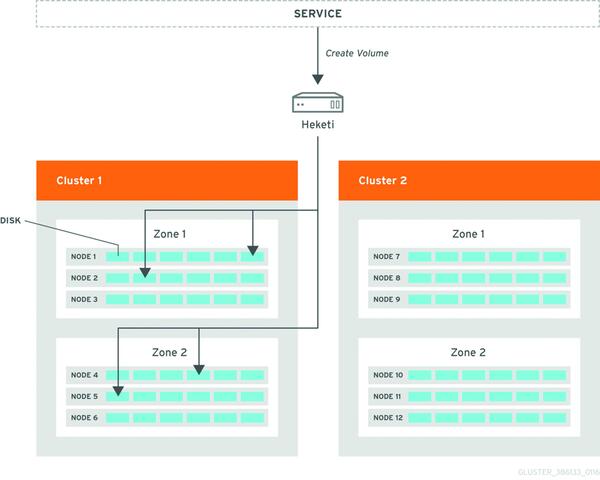 Bild 3: Heketi kann dynamisch Gluster-Storage provisionieren, sodass das Anlegen von Volumes nicht mehr manuell erfolgen muss.
Bild 3: Heketi kann dynamisch Gluster-Storage provisionieren, sodass das Anlegen von Volumes nicht mehr manuell erfolgen muss.
Zum besseren Verständnis des Setups folgt eine kurze Einführung in das OpenShift-PaaS-Framework, bevor es dann an die eigentliche Konfiguration des Storage-Systems geht. OpenShift verwendet eine Microservice-basierte Architektur, bei der mehrere Komponenten zum Einsatz kommen. So kümmert sich beispielsweise Docker darum, die erforderlichen Laufzeitumgebungen für die eigentlichen Anwendungen, die unter OpenShift betrieben werden sollen, innerhalb von Containern zur Verfügung zu stellen. Zur Orchestrierung dieser Container kommt Kubernetes zum Einsatz. Das Framework besteht aus einer ganzen Reihe von Services, von denen einige auf einem Steuerungssystem, dem sogenannten Master-Knoten, andere auf den einzelnen Docker-Hosts, den Nodes, laufen.
Auf dem Master-Knoten existiert ein API-Service, der zur Steuerung der einzelnen Kubernetes-Services zum Einsatz kommt und sich auch um die Container auf den einzelnen Nodes kümmert. In der Kubernetes-Welt werden die Container-Objekte als Pods bezeichnet. Ein solcher Pod kann lediglich einen einzelnen oder auch mehrere Container enthalten. Eine Datei im YAML-Format enthält alle notwendigen Informationen über einen solchen Pod. Beispielsweise, welches Image für die Container eines Pods zum Einsatz kommen soll und auf welchem Port die Dienste innerhalb der Container lauschen sollen. Informationen über das Volume, auf das der Pod zugreifen soll, sind ebenfalls Teil dieser YAML-Datei. Andere Objekte in Kubernetes werden meistens über JSON-Dateien beschrieben und innerhalb von OpenShift mit dem Kommandozeilentool oc erzeugt.
Listing 1: gluster-endpoint.json
{
"kind": "Endpoints",
"apiVersion": "v1",
"metadata": {
"name": "glusterfs-cluster"
},
"subsets": [
{
"addresses": [
{
"ip": "192.168.121.101"
}
],
"ports": [
{
"port": 1
}
]
},
{
"addresses": [
{
"ip": "192.168.121.102"
}
],
"ports": [
{
"port": 1
}
]
},
{
"addresses": [
{
"ip": "192.168.121.103"
}
],
"ports": [
{
"port": 1
}
]
}
]
}
Auf den einzelnen OpenShift-Nodes läuft ein Kubernetes-Agent-Service mit dem Namen kubelet. Der kubelet-Service stellt sicher, dass die Pods oder auch andere Kubernetes-Objekte den jeweiligen Beschreibungen aus den zuvor erwähnten YAML- oder JSON-Dateien entsprechen. Dies wird kontinuierlich verifiziert. Sollte beispielsweise ein bestimmter Service aus vier Containern bestehen, es stehen aber nur noch drei Container zur Verfügung, kümmert sich der kubelet-Service darum, einen zusätzlichen Container zu starten, sodass die zuvor definierten Anforderungen wieder erfüllt sind.
Ähnliche Artikel
-
Kubernetes-Distribution OpenShift (2)

-
Red Hat bringt QuickStart Cloud Installer
Ein neues Tool soll die Installation privater Clouds vereinfachen.
-
Storage-Management für Kubernetes

-
Container-Vorlagen erstellen und ausrollen

-
Storage-Pools mit GlusterFS aufbauen

Konfigurationsmanagement

Themen


