
Monitoring und Ceph
Wichtig im administrativen Alltag ist zweifellos das Thema Monitoring. Für Ceph ergeben sich dabei erstmal verschiedene Möglichkeiten: Ceph selbst weiß ja über den Zustand jedes einzelnen OSDs Bescheid, sodass es durchaus möglich wäre, die OSDs per Monitoring-Applikation auch einzeln zu überwachen. Das Problem: Für keine der etablierten Monitoring-Lösungen ist das bereits in Form von Code vorhanden. Ganz ohne Monitoring müssen Ceph-Benutzer trotzdem nicht auskommen, denn unter
[1]
steht ein rudimentäres Nagios-Plugin bereit, das wenigstens die Ausgabe von
»ceph health«
parsen und dann entsprechende Status-Meldungen im Monitoring anzeigen kann. Außerdem arbeitet Inktank laut eigener Aussage intensiv an besserer Unterstützung der gängigen Monitoring-Tools, sodass an dieser Front in Kürze einige Neuerungen zu erwarten sein dürften.
Admin-Sockets
Schließlich noch ein kleiner Tipp für Admins, die detailliert wissen wollen, was ihr Ceph gerade tut: In Ceph besteht die Möglichkeit, mittels der sogenannten
»Admin Sockets«
genaue Performance-Daten zu erhalten. Die Sockets liegen üblicherweise in
»/var/run/ceph«
und ihr Name endet auf
».asok«
(
Abbildung 5
). Die aktuellen Performance-Daten eines OSDs auf Charlie ließen sich beispielsweise unter der Prämisse, dass das OSD die ID 3 hat, so finden:
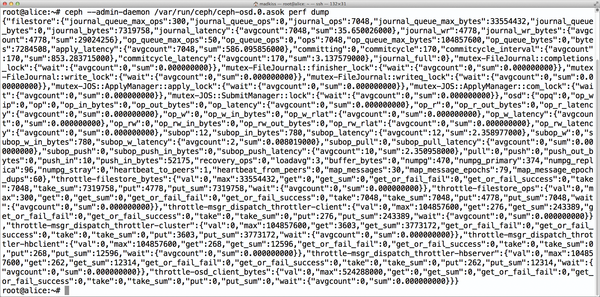 Abbildung 5: Performance-Daten lassen sich über die Admin-Sockets erfragen. Weil es sich um JSON-Ausgaben handelt, empfiehlt es sich, den Output durch …
Abbildung 5: Performance-Daten lassen sich über die Admin-Sockets erfragen. Weil es sich um JSON-Ausgaben handelt, empfiehlt es sich, den Output durch …
ceph --admin-daemon /var/run/ceph/ceph-osd.3.asok perf dump
Die Ausgabe besteht aus JSON-Output. Durch ein angehängtes
»| python -m json.tool«
an den vorherigen Befehl lässt sich die Ausgabe lesbar machen (
Abbildung 6
).
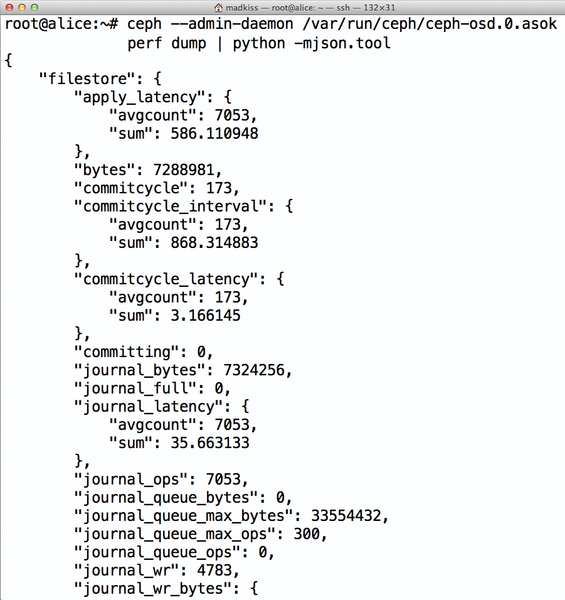 Abbildung 6: … den Befehl python -mjson.tool zu schicken – dann kommt eine lesbare Ausgabe heraus.
Abbildung 6: … den Befehl python -mjson.tool zu schicken – dann kommt eine lesbare Ausgabe heraus.
Placement-Group-Statusmeldungen
Down: Es gibt im Cluster keinen Datenträger mehr, der die Objekte der PG hat. Die Placement Group ist also offline.
Peering: Eine PG durchläuft gerade den sogenannten Peering-Prozess, bei dem der Zustand der PG auf verschiedenen OSDs miteinander verglichen wird.
Inconsistent: Ceph hat festgestellt, dass Placement Groups über verschiedene OSDs hinweg nicht konsistent sind.
Scrubbing: Check überprüft die Placement Group gerade auf Inkonsistenzen.
Repair: Ceph korrigiert gerade inkonsistente Placement Groups, damit diese wieder den Replikationsanforderungen genügen.
Degraded: Von einer Placement Group existieren innerhalb des Clusters nicht so viele Replikas, wie die Replikations-Policy vorgibt.
Stale: Ceph hat von den OSDs, die die betroffene Placement Group haben sollte, keine Informationen über den Zustand der Placement Group erhalten, seit sich die Zuordnung der Placement Groups zu den OSDs zum letzten Mal geändert hat.
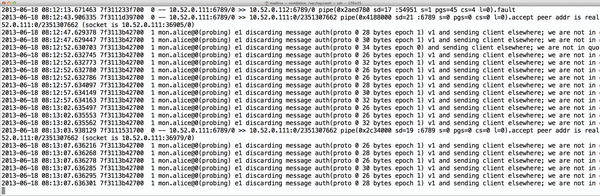 Abbildung 4: Ein Monitoring-Server, der nicht mehr genug andere MONs sieht, schickt Clients mit Anfragen – wie zu erkennen – woanders hin.
Abbildung 4: Ein Monitoring-Server, der nicht mehr genug andere MONs sieht, schickt Clients mit Anfragen – wie zu erkennen – woanders hin.
Infos
- Rudimentäres Ceph-Plugin für Nagios: https://github.com/ceph/ceph-nagios-plugin
Ähnliche Artikel





Cluster-Zustand mit Ceph-Dashboard verwalten
Konfigurationsmanagement

Themen


