Log-Management mit Logstash

Die Nadel im Heu

Schon
auf einem kleinen LAMP-Server steht man einer Vielzahl an Logfiles gegenüber, die bei Problemen durchsucht werden müssen. Neben den vielen Standard-Logs des Systems wie
»syslog«
oder
»mail.log«
schreiben Dienste wie Apache und MySQL noch zusätzlich fleissig weitere Einträge in ihre Logs. Kann man das betroffene Subsystem bei Problemen bereits isolieren, ist schon ein großer Schritt getan. Ein MySQL-Fehler lässt sich dann bereits sicher finden, wenn man weiß, wann er ungefähr aufgetreten ist. Wird die eigene Web-Applikation allerdings auf der Basis eines Tomcat im Multi-Node-Cluster ausgeliefert, ist es schon deutlich schwieriger, die richtige Stelle im Log zu finden.
Richtig kompliziert wird es dann, wenn ein Fehler seine Spuren in den Logs über mehrere Komponenten und Systeme hinweg hinterlässt, aber genaue Informationen über Zeit und Fehlerquelle fehlen. Spätestens dann geht dem Admin mit normalen Bordmitteln schnell die Luft aus und der Suchaufwand steigt exponentiell an. Die diversen Log-Informationen von verschiedenen Systemen zeitlich und inhaltlich richtig auszuwerten, setzt dann voraus, dass man sich im Vorfeld bereits mit den verschiedenen Quellen, Formaten und Inhalten auseinandergesetzt hat. Wer dabei im Vorhinein Zeit in ein Tool wie Logstash investiert hat, wird jetzt schnell mit einer erstklassigen Analyse und einem schnellen Zugriff auf aktuelle und historische Daten belohnt.
Ordnung ist das halbe Leben
Auf seine Grundfunktion reduziert ist Logstash [1] eine netzwerkfähige Pipe mit verschiedenen Filtermöglichkeiten. Seine Aufgabe besteht darin, Meldungen aus verschiedenen Inputs zu empfangen, zu filtern und dann an einen oder mehrere Outputs weiterzuleiten. Logstash kümmert sich bewusst nur um die Steuerung und Filterung der verschiedenen Kanäle, aber nicht um deren Speicherung. Für das kurzfristige Caching von Events, die Indizierung und Langzeitspeicherung von Log-Informationen setzt Logstash auf zwei weitere Open-Source-Komponenten.
Für die kurzzeitige Speicherung und Vermittlung von Events verbindet sich Logstash als Ein- und Ausgabekanal mit Redis [2] . Redis hat in einer der letzten Versionen RabbitMQ abgelöst, das früher diese Funktion übernahm, und dient als speicherbasierter Key-Value-Store. Redis selbst hat keine externen Abhängigkeiten und dient im Zusammenspiel mit Logstash als Broker für die verschiedenen Eingangskanäle. Diese Entkopplung des Datenflusses ist aus zwei Gesichtspunkten von großer Bedeutung. Zum einen stellt es die schnelle Annahme der verschiedenen Log-Shipper sicher und verhindert so einen möglichen Engpass bei der Zulieferung von Log-Informationen. Zum anderen speichert es bei Ausfall oder Überlastung der weiterverarbeitenden Logstash-Instanz(en) alle Daten so lange, bis die Instanzen ordnungsgemäß weiterarbeiten können. Stoppt die Redis-Instanz oder startet sie neu, lassen sich die Daten im Filesystem zwischenspeichern, damit die Log-Informationen lückenlos bleiben.
Um Log-Daten zu indizieren oder langfristig zu archivieren, bedient sich Logstash der Dienste von ElasticSearch. ElasticSearch [3] ist ein Open-Source-Suchserver auf Basis von Apache Lucene [4] , der die Log-Informationen speichert, indiziert und eine schnelle Suche via REST-Interface ermöglicht. ElasticSearch bringt alles mit, was zur Skalierung und Verteilung der Daten notwendig ist, ist performant und leicht bedienbar. Bei der ersten Speicherung von Log-Informationen kümmert sich ElasticSearch automatisch um die Erzeugung des benötigten Daten-Schemas.
ElasticSearch erlaubt die Administration und Konfiguration nahezu aller relevanten Parameter ebenfalls via REST-Interface. Wer eine visuelle Konfiguration vorzieht, kann zu freien Alternativen wie ElasticHQ [5] greifen. Die Verwendung von Logstash setzt grundsätzlich kein tieferes Know-how im Umgang mit ElasticSearch voraus. Wer bereits zu Beginn mit größeren Datenmengen konfrontiert ist und die Hochverfügbarkeit der Log-Informationen gewährleisten muss, dem sei eine Einarbeitung in die verschiedenen Begrifflichkeiten wie Nodes, Shards und Replicas dringend empfohlen.
Die offizielle Installationsdokumentation [6] von ElasticSearch ist für kleine Umgebungen absolut ausreichend und simpel, jedoch in Bezug auf die angesprochenen verteilten Umgebungen etwas dünn. Leider gibt auch die verfügbare Fachliteratur an dieser Stelle nicht viel her und so bleibt einem bei Bedarf externe Unterstützung oder die Recherche im Web [7] .
Zusammen ergeben diese verschiedenen Komponenten eine skalierbare, flexible und verlässliche Gesamtarchitektur ( Abbildung 1 ), die vielen kommerziellen Alternativen wie beispielsweise Splunk ebenbürtig, wenn nicht sogar überlegen ist.
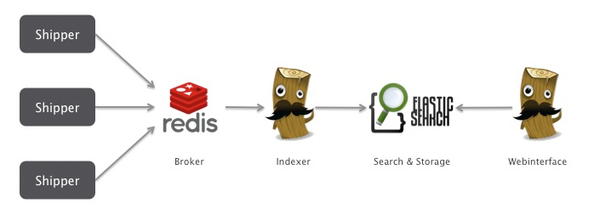 Abbildung 1: Logstash in der Architektur-Übersicht.
Abbildung 1: Logstash in der Architektur-Übersicht.
Log-Verarbeitung
Die Inbetriebnahme ist absolut problemlos. Mit Ausnahme von Redis können alle Komponenten sofort nach dem Download entpackt und gestartet werden. Bei ElasicSearch ist hier lediglich der Aufruf von
»bin/elasticsearch«
notwendig und der Suchserver ist wenige Sekunden später verfügbar. Logstash selbst wird ebenfalls als auf JRuby basierende Java-Applikation ausgeliefert und ist nach Aufruf von
java -jar Logstash-x.x.x-flatjar.jar agent -f logstash-config.conf
bereit. Wer kein passendes Paket für Redis findet, muss nach Ausführung von
»make«
und
»make install«
ebenfalls nur das Binary
»redis-server«
starten und fertig. Für den etwas eleganteren Betrieb mittels Service-Skript stehen bei allen Projekten entsprechende Wrapper-Skripte zur Verfügung.
Die Anlieferung, das sogenannte Log-Shipping, kann mit Logstash selbst, Lumberjack oder einem Standardmechanismus wie etwa Syslog erfolgen. Listing 1 liest ein Apache-Access-Log aus der beschriebenen Input-Source und leitet dieses an eine lokale Redis-Instanz weiter. Ebenfalls zu erkennen ist, dass die Daten zusätzlich als Debug-Messages ausgegeben werden.
Listing 1
Beispiel Access-Log
Nach dem Start von Logstash werden alle Informationen des Apache-Access-Files an Redis übertragen und bis zur Weiterverarbeitung zwischengespeichert. Logstash kümmert sich selbstständig um die richtige Fileposition und Log-Rotation und wartet am Ende auf die Aktualisierung der Datenquelle.
Mit einer zweiten Logstash-Konfiguration (
Listing 2
) werden die Daten aus dem Redis-Server gelesen und direkt in ElasticSearch geschrieben. Wichtig ist an dieser Stelle der entsprechende key (
»logstash.apache«
), der den expliziten Zugriff auf die in der vorherigen Instanz erstellten Informationen ermöglicht. Dieses einfache Beispiel ist selbstverständlich auch in einer Konfiguration kombinierbar und ermöglicht die direkte Übertragung der Apache-Logs zu ElasticSearch. Da Redis für eine Vielzahl an Log-Lieferanten als Eingangskanal dienen kann und wie bereits oben erwähnt eine entkoppelte Zwischenspeicherung möglich macht, ist dessen Verwendung jedoch zu favorisieren.
Listing 2
Daten in ElasticSearch
Für die Verarbeitung diverser Datenquellen unterstützt Logstash nahezu alle gängigen Formate [9] . Besonders elegant und einfach ist der integrierte Grok-Filter [10] , der ein breites Set an Basis-Patterns für die Filterung von Logs und deren Inhalten zur Verfügung stellt. So können unstrukturierte Log-Informationen in Form gebracht und harmonisiert werden, um die spätere Weiterverarbeitung zu erleichtern. Andere Filter erlauben auch Veränderungen oder Ergänzungen. Der GeoIP-Filter fügt beispielsweise auf Grundlage von IP-Adressen die jeweiligen Geo-Informationen hinzu. Diese werden ebenfalls gespeichert und erlauben am Beispiel eines Apache-Logs eine regionale Auswertung von Seiten-Zugriffen.
Besondere Erwähnung verdient an dieser Stelle auch noch der Multline-Filter, der aufbauend auf Patterns eine zeilenübergreifende Strukturierung von Log-Informationen ermöglicht. So können etwa alle Zeilen des Stack Traces zu einem Event zusammengefasst werden, was sowohl die spätere Analyse als auch die Anwendung zusätzlicher Filter vereinfacht.
Ähnliche Artikel
-
Loganalyse mit dem ELK-Stack (2)
-
Workshop: Open Source-Tools zum Log-Management unter Linux

-
Loganalyse mit dem ELK-Stack (1)

-
Loganalyse mit dem ELK-Stack (3)

-
Logzoom: schnellerer Ersatz für Logstash
Weil Logstash und Fluentd nicht die Anforderungen erfüllten, hat die Firma Packetzoom einen Ersatz dafür geschrieben und unter einer freien Lizenz veröffentlicht.
Konfigurationsmanagement

Themen


