ZFS - Snapshots, RAID und Datensicherheit
ZFS - Snapshots, RAID und Datensicherheit
Immer größere Datenmengen verlangen nach größeren Filesystemen, doch die traditionellen Lösungen geraten an ihre Grenzen. Nach Moores Gesetz reichen 64 Bit breite Adressen schon im nächsten Jahrzehnt nicht mehr aus. ZFS dagegen arbeitet intern mit 128-Bit-Adressen und ist damit für die absehbare Zukunft gut gewappnet. Das aber ist nur einer seiner Vorteile.
Ebenso wichtig ist etwa die Integrität der Daten. Wird sie verletzt, könnte das zum Beispiel einen Filesystemcheck nötig machen, der auf die herkömmliche Art auf einem sehr großen Volume mehrere Tage dauerte. Aber ZFS kommt ohne jeden Filesystemcheck aus und bietet dennoch mehr Sicherheit. Es validiert jeden Block anhand einer Prüfsumme und integriert einen Volume-Manager direkt in das Filesystem. Darüber hinaus verwendet es das Transaktionsprinzip, um zu jedem Zeitpunkt einen konsistenten Zustand zu garantieren. Trotz aller Komplexität bleibt die Administration aber überschaubar: Zum Beispiel lässt sich mit nur einem Kommando ein ZFS-Pool mit Filesystem erzeugen.
Entwicklung von ZFS
Bisherige Filesysteme haben ihre Ursprünge in den 60er und 70er Jahren des vorigen Jahrhunderts. Die Voraussetzungen zu dieser Zeit waren andere als heute: Damals war Plattenspeicher teuer, weshalb man die Strukturen auf der Platte äußerst sparsam auslegte. Bei den Datenstrukturen für Metadaten knauserte man mit jedem Bit und legte die Allokationstabellen dynamisch an (siehe heutige Inode-Struktur in UFS oder die FAT-Struktur).
Als sich Anfang der 90er Jahre der Plattenplatz verbilligte, entstand das Bedürfnis nach neuen Funktionen. Man wollte gespiegelte Platten haben, dank derer das System auch beim Ausfall einer Platte weiterläuft. Oder man verwendete Striping mehrerer Platten, um höhere Performance zu erzielen (mehr parallele Zugriffe, höhere Datenrate). Es kamen Volume-Manager auf (wie der Solaris Volume-Manager oder der Linux-LVM), die eine Menge physischer Platten zu logischen Einheiten zusammenfassen. Gebräuchlich war die Terminologie des ursprünglichen RAID-Papiers [1] von David A. Patterson, obwohl er eigentlich das beschreibt, was heute ein Storage-Subsystem ist.
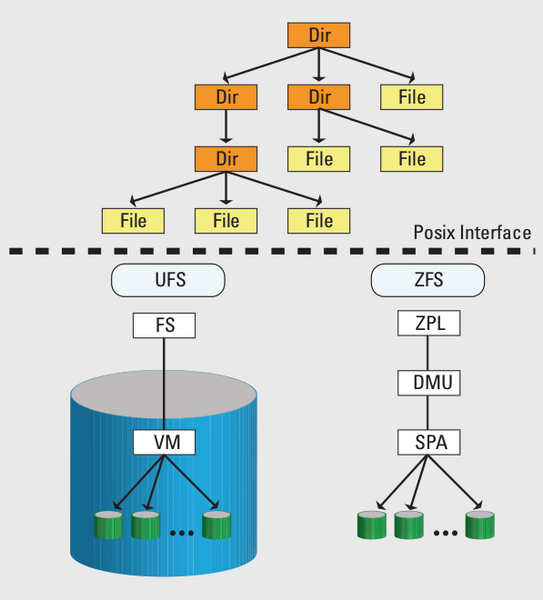 Abbildung 1: Die Architektur von ZFS und UFS im Vergleich. Bei ZFS gibt es keinen externen Volume-Manager mehr, er ist in das Filesystem integriert.
Abbildung 1: Die Architektur von ZFS und UFS im Vergleich. Bei ZFS gibt es keinen externen Volume-Manager mehr, er ist in das Filesystem integriert.
Die Krux an dieser Stelle ist, dass die Entwickler dabei die alten Filesysteme beibehielten. Das schien auf den den ersten Blick auch logisch, ließen sie sich doch problemlos auch auf den Volumes verwenden, die ein Volume-Manager erzeugt hatte. Allerdings lässt sich dann das Filesystem nicht mehr für die Hardware optimieren, weil es die physische Struktur unter der Ebene des Volume nicht kennt. Und auch der VolumeManager kann nichts mehr optimieren, weil er die verwendeten Adressen nicht verändern darf und die Schreibreihenfolge einhalten muss, die das Filesystem vorgibt. ZFS durchbricht diese Sackgasse, indem es die Volume-Manager-Funktion in das Filesystem integriert. Der Preis dafür war, dass sich nichts von vorigen Entwicklungen übernehmen ließ, die Entwickler mussten bei Null beginnen. Die Vorgaben für das Design waren:
- Pooled Storage: ZFS operiert auf einer Menge von Platten und erzeugt die nötige Redundanz selbst.
- Unter-Filesysteme: ZFS vereinfacht sich die Administration durch Aufteilung in kleinere Einheiten, die Einstellungen vererben.
- Datenintegrität: Von der Platte bis zum Hauptspeicher sichert ZFS alle Blöcke durch Prüfsummen. Diese Prüfsummen kann dieSoftware im Hauptspeicher nachprüfen undso nicht nur die Inhalte auf der Platte, sondern auch die Transportpfade sichern.
- Transaktionen: Dadurch sind die Daten aufder Platte zu jedem Zeitpunkt konsistent und der Filesystemcheck (fsck) entfällt vollständig. Außerdem verbessern die Transaktionensogar die Performance beim Schreiben.
Die Architektur von ZFS
UFS, das bisherige Filesystem in Solaris, und ZFS bieten die gleiche hierarchische Sicht auf Verzeichnisse und Dateien (Abbildung 1). Unterhalb des POSIX-Interface sind die Filesysteme jedoch ganz verschieden implementiert. Ein UFS Filesystem residiert in genau einer Partition, die auch auf einem logischen Volume liegen darf. Dabei abstrahiert es die Details der Plattenkonfiguration, sie sind für Filesystem nicht sichtbar. UFS speichert die Metadaten kompakt in besonderen Strukturen, deren Erzeugung Zeit kostet.
In ZFS implementiert das Filesystem der ZPL (ZFS POSIX Layer). Zur Speicherung der Dateien und der Metadaten verwendet ZFS Objekte im ZFS-Plattenpool (»zpool«), die die DMU (Data Management Unit) zur Verfügung stellt. Löst das Betriebssystem nun eine Schreiboperation aus, startet die DMU eine Transaktion. Anschließend sammelt sie gleichzeitig abgeschlossene Transaktionen in so genannten Transaktionsgruppen, die der SPA (Storage Pool Allocator) etwa alle fünf Sekunden auf die Platte schreibt. Der SPA allokiert erst die Position für die zu schreibenden Blöcke und schreibt dann die Daten transaktionell mit Copy-on-Write. Er verwendet dazu ausschließlich Blöcke, die zu diesem Zeitpunkt unbenutzt sind. Außerdem allokiert er die Blöcke so, dass er sie möglichst effizient schreiben kann.
Fallen beim Schreiben viele kleine, zufällig verteilte Blöcke an (Random Writes), dann muss UFS jeden einzelnen dieser Blöcke überschreiben, was sehr viele Kopfbewegungen auf den Platten erzeugt. Dadurch sind Random Writes in UFS langsam.
ZFS generiert aus den Random Writes wenige sequenzielle Schreibvorgänge (Sequential Writes), indem es die Blöcke geeignet allokiert. Dadurch bedarf es nur weniger Kopfbewegungen und die Schreibperformance ist viel größer. ZFS speichert die Daten dabei zuerst in einem Log (ZIL, ZFS Intent Log), das zur Sicherung vor Systemabbrüchen dient. Jede Transaktion leert am Ende dieses Log.
Ähnliche Artikel
-
ZFS unter FreeBSD – Datensicherheit auf neuen Wegen

-
Ein Btrfs-Praxis-Check und -Workshop

-
Infortrend baut EonNAS-Familie aus
Die Speicherlösungen der EonNAS-Familie von Infortrend erhalten leistungsstarken Zuwachs.
-
Experimenteller Windows-Support für Deduplication-Filesystem
Das von Opendedup entwickelte Deduplikations-Dateisystem SDFS wurde nun auf Windows portiert.
-
Linux-Dateisysteme administrieren (1)

Konfigurationsmanagement

Themen


