Der RADOS-Objectstore und Ceph, Teil 2

Storage-Magie

Das vorletzte ADMIN-Magazin hat RADOS und Ceph vorgestellt und vermittelt, was es damit auf sich hat. Der zweite Teil sieht nun genauer hin und erläutert die grundlegenden Konzepte, die bei ihrer Entwicklung eine Rolle spielen. Wie sorgt der Cluster zum Beispiel für die interne Redundanz der abgelegten Objekte? Und welche Möglichkeiten existieren neben Ceph noch, um an die Daten aus dem Object Store heranzukommen?
Bereits die erste Folge des Workshops demonstrierte, wie ein existierender Cluster um einen Knoten zu erweitern ist (
»ceph osd crush add 4 osd.4 1.0 pool=default host=daisy«
unter der Annahme, dass der Hostname des neuen Servers
»daisy«
ist). Der Befehl bewirkt, dass der Host
»daisy«
zum Teil des Clusters wird und das gleiche Gewicht (1,0) erhält wie alle anderen Knoten. So leicht wie das Hinzufügen eines Knotens zur Clusterkonfiguration gerät auch das Entfernen. Der passende Befehl lautet:
»ceph osd crush remove osd.4«
. Der Parameter
»pool=default«
beim Hinzufügen weist dabei schon auf ein wichtiges Feature hin: die Pools.
Mit Pools arbeiten
RADOS hat die Möglichkeit, den zusammenhängenden Speicher des Object Stores zu unterteilen. Die einzelnen Fragmente heißen Pools. Dabei entspricht ein Pool keinem zusammenhängenden Speicherbereich wie bei einer Partition, sondern bildet eine logische Ebene aus entsprechend der Poolzugehörigkeit getagten Binärdaten. Pools erlauben beispielsweise Konfigurationen, innerhalb derer einzelne Benutzer nur auf bestimmte Pools zugreifen dürfen. In der Default-Konfiguration stehen die Pools
»metadata«
,
»data«
und
»rbd«
zur Verfügung. Eine Übersicht über alle vorhandenen Pools ist mit
»rados lspools«
zu bekommen (
Abbildung 1
).
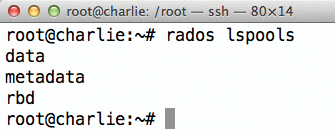 Abbildung 1: rados lspool zeigt die Pools an, die RADOS im Augenblick kennt.
Abbildung 1: rados lspool zeigt die Pools an, die RADOS im Augenblick kennt.
Wer die Konfiguration um einen zusätzlichen Pool erweitern will, nutzt den Befehl
»rados mkpool
Name
«
, wobei
Name
durch einen entsprechend eindeutigen Namen zu ersetzen ist. Soll ein vorhandener Pool verschwinden, funktioniert
»rados rmpool
Name
«
.
RADOS-Interna: Placement Groups und die Crushmap
Eines der ausdrücklichen Design-Ziele von RADOS ist es, nahtlos skalierbares Storage zu bieten. Dafür sollen Admins die Möglichkeit haben, einen RADOS-Objectstore jederzeit um beliebig viele Speicherknoten zu vergrößern. Von entscheidender Bedeutung ist dabei das Thema Redundanz. RADOS trägt ihm Rechnung, indem es sich selbstständig um die Replikation von Daten kümmert, ohne dass der Admin des RADOS-Clusters händisch einzugreifen braucht. Aus der Kombination mit Skalierbarkeit ergibt sich dabei für RADOS ein Problem, mit dem sich andere Replikationslösungen nicht herumschlagen: Wie lassen sich Daten innerhalb eines größeren Clusters bestmöglich verteilen?
Zur Erinnerung: Herkömmliche Storage-Lösungen kümmern sich in aller Regel "nur" darum, dass Daten von einem Server auf den anderen kopiert werden, damit im Zweifelsfalle ein Failover stattfinden kann. Meist laufen solche Lösungen überhaupt nur innerhalb eines Clusters mit zwei oder höchstens drei Knoten, dass weitere Knoten hinzukommen, ist von vorneherein ausgeschlossen.
Bei RADOS geht das nicht: Hier können theoretisch beliebig viele Knoten in den Cluster aufgenommen werden, und bei jedem muss sich der Object Store darum kümmern, dass auch dessen Inhalte innerhalb des gesamten Clusters redundant verfügbar sind. Nicht zuletzt steht den Entwicklern obendrein auch noch das Thema "Rack Awareness" ins Haus: Wer einen 20-Knoten-Cluster mit RADOS in seinem Rechenzentrum stehen hat, wird dessen Knoten idealerweise auf mehrere Brandabschnitte oder Gebäude verteilen wollen, um so für zusätzliche Sicherheit zu sorgen. Damit das funktioniert, muss die Speicherlösung allerdings wissen, welcher Knoten wo steht und welche Daten wo und wie zu bekommen sind. Die Lösung für dieses Problem, die sich die Entwickler von RADOS und allen voran RADOS-Guru Sage A. Weil ausdachten, besteht aus zwei Teilen: den Placement Groups und der Crushmap.
Ähnliche Artikel





Konfigurationsmanagement

Themen


