ADMIN-Tipp: Parallele Linux-Shell
Prozessoren mit mehreren Kernen statt immer höherer Taktfrequenz beschleunigen inzwischen selbst Smartphones und Laptops der unteren Preisklasse. Betriebssysteme, Benutzeroberflächen und viele Anwendungen setzen fast selbstverständlich auf Parallelbetrieb. Nur die Linux-Shell läuft nach wie vor im alten sequentiellen Betrieb: Ein Befehl folgt brav dem anderen.
Das Gnu-Werkzeug Parallel schafft jedoch Abhilfe. Ohne dass der Anwender sich um die Verwaltung von Ressourcen oder um die Aufteilung von Eingabedaten kümmern muss, nutzt das Werkzeug die über die Prozessorkerne verteilte Rechnerleistung aus.
Das Perl-Script Parallel findet sich bei den meisten Distributionen in einem eigenen, gleichnamigen Paket. Beim Aufruf liest es die auszuführenden Kommandos von STDIN; alternativ teilt es eine zu verarbeitende Datei auf und wendet einen Befehl auf die einzelnen Bestandteile an.
Beispielsweise komprimiert der folgende Befehl mehrere Dateien in einem Verzeichnis gleichzeitig:
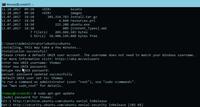
$ ls | parallel gzip {}
Die Ausgabe von ls lässt sich hierbei beliebig einschränken oder durch ein anderes Werkzeug wie find ersetzen. Ein Paar geschweifter Klammern "{}" steht als Platzhalter für eine Eingabezeile zur Verfügung, so dass sie sich als Argument für einen Befehl verwenden lässt. Eine alternative Schreibweise nimmt Eingabeargumente direkt entgegen:
$ parallel gzip ::: datei1 datei2 datei3
Das Kommandozeilenargument "-j" definiert die Anzahl der nebenläufig auszuführenden Jobs. Standardmäßig startet Parallel so viele Prozesse gleichzeitig wie Prozessoren beziehungsweise Kerne zur Verfügung stehen. Die Angabe lässt sich auch in Prozent und relativ zur Anzahl der Prozessoren definieren, beispielsweise führt die Angabe von "-j 150%" dazu, dass jede CPU mit 1,5 Jobs versorgt wird. Diese Zahl gilt als gute Faustregel, um eine dauerhafte Vollauslastung zu erzielen, da die leichte Überbelegung Prozessorleerlauf während längerer Festplattenzugriffe entgegewirkt.
Falls bei der Ausgabe der parallelen Jobs die Reihenfolge wichtig ist, sorgt das Argument "-k" dafür, dass diese der Eingabereihenfolge entspricht, egal wie schnell die Teilprozesse die Verarbeitung abschließen. Ohne diese Angabe lässt sich nicht vorhersagen, in welcher Reihenfolge die Einzelergebnisse eintreffen, da viele praktisch unberechenbare Faktoren einzelne Prozesse verzögern oder beschleunigen können.
Soll ein Befehl eine oder mehrere Dateien abarbeiten, hilft das Argument "--pipe". Der folgende Befehl zerlegt beispielsweise eine Datei zeilenweise und füttert sie an mehrere nebeneinander laufende grep-Prozesse:
$ parallel -j 150% -k --pipe grep "ERROR" programm.log
Im Fall von grep bietet sich die zeilenweise Verarbeitung zwar an, aber andere Befehle bevorzugen möglicherweise andere Eigabeblöcke. In diesem Fall definieren die Argumente "--recstart" und "--recend" die Zeichen, die anstelle von Zeilenumbrüchen als Markierungen für Beginn beziehungsweise Ende einer Einheit dienen.
Bei der Parallelisierungswut darf ein Hinweis jedoch nicht fehlen: In vielen Fällen, in denen Bash-Prozesses viel Zeit benötigen, liegt das gar nicht am Prozessor. Der Flaschenhals ist häufig die Festplatte mit ihren vergleichsweise lange Lese- und Schreibzugriffszeiten. In diesem Fall hilft es leider nichts, die eingehenden Daten auf mehrere Prozessoren zu verteilen.
Ähnliche Artikel
-
Die Tipps des Monats

-
Windows Server 1709
-
ADMIN-Tipp: Find-Tutorial (2)
Nachdem der erste Teil des Find-Tutorial die Basics des Programms erklärt hat, soll es dieses Mal darum gehen, wie man die gefundenen Dateien weiterverarbeiten kann.
-
ADMIN-Tipp: Capslock unter Linux abschalten
HATTEN SIE SCHON MAL VERSEHENTLICH DIE CAPSLOCK-TASTE GEDRÜCKT? Mit der passenden Konfiguration schaffen Sie diese Altlast aus der Welt und führen die Taste einer besseren Verwendung zu.
-
ADMIN-Tipp: Pfade herauspicken
Wer kennt das nicht: Ein Bash-Kommando spuckt eine endlose Liste von Pfaden und Dateien aus, von denen der geplagte Anwender die interessanten per Copy-und-Paste verarbeitet. Ein Facebook-Tool erleichtert diese Arbeit.
Konfigurationsmanagement

Themen


